BioCLIP 是一个利用图像和结构化生物知识回答生物学问题的多模态大模型。通过在生命之树(生物学分类)上训练模型,增强了对自然界层次结构的理解,具有强大的可泛化性。文章还创建了 TreeOfLife-10M 生物图像数据集,代码和数据集均已开源。
![图片[1]-CVPR 2014| BioCLIP:生命之树的视觉基础模型 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2024/05/Pasted-image-20240529102331.png)
摘要
- 文章指出,自然世界图像的收集变得越来越普遍,这些图像是生物信息的重要来源。
- 尽管目前有许多计算方法和工具(特别是计算机视觉)可以从图像中提取与生物学相关的信息,但这些方法大多是为特定任务设计的,不易适应或扩展到新问题、新环境和新数据集。
- 作者提出了开发一个通用的生物图像视觉模型的需求,并为此创建并发布了 TREEOFLIFE-10M,这是一个包含超过1000万个图像、覆盖生物分类树中45万多个分类群的大规模且多样化的机器学习(ML)数据集。
- 接着,作者介绍了 BioCLIP 模型,这是一个利用 TREEOFLIFE-10M 数据集的独特属性(包括丰富的植物、动物和真菌图像以及可用的丰富结构化生物学知识)开发的生物分类树的基础模型。
- 通过在多种细粒度生物学分类任务上的严格基准测试,作者发现 BioCLIP 在性能上一致且显著地优于现有基线(提高了16%到17%的绝对精度)。
- 内在评估揭示 BioCLIP 学习到了符合生命之树的层次表示,这表明了其强大的泛化能力。
![图片[2]-CVPR 2014| BioCLIP:生命之树的视觉基础模型 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2024/05/Pasted-image-20240529101231.png)
背景
在数字化时代,我们如何利用科技探索和保护生物多样性?随着自然世界图像的爆炸性增长,将这些图像快速转换为可操作信息(例如物种分类、个体识别和特征检测)的能力,可以加速并促进物种划分、适应机制理解、种群结构估计和生物多样性监测与保护等任务。然而,如何有效利用这些数据是一个很大的挑战。尽管目前有许多方法可以从图像中提取与生物学相关的信息,但这些方法大多是为特定任务设计的,不易适应或扩展到新问题、新环境和新数据集。为了解决这一问题,文章开发了BioCLIP——一款为生命之树量身打造的视觉基础模型。
数据集
模型的训练离不开一个庞大且多样化的数据集:TREEOFLIFE-10M。文章介绍了 TREEOFLIFE-10M 数据集的创建过程,包括图像和元数据的聚合。这个数据集包含了超过1000万个图像,涵盖了生物分类树上的45万多个分类群。它不仅整合了现有的高质量数据集,如 iNat21 和 BIOSCAN-1M,还包括了从 Encyclopedia of Life (EOL) 新整理的图像,极大地丰富了数据的多样性。
![图片[3]-CVPR 2014| BioCLIP:生命之树的视觉基础模型 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2024/05/Pasted-image-20240529100954.png)
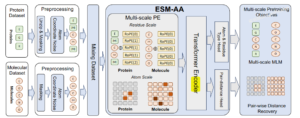
模型架构与训练
BioCLIP 模型是基于 OpenAI 的 CLIP (Contrastive Language–Image Pre-training) 模型进行扩展和改进的。CLIP 模型本身由两个主要部分组成:一个视觉编码器和一个文本编码器,它们共同工作以学习图像和文本之间的关联。以下是 BioCLIP 模型架构的主要特点:
- 初始化:BioCLIP 从 OpenAI 的 CLIP 模型权重开始初始化,使用了 CLIP 模型的预训练参数作为起点。
- 视觉编码器:BioCLIP 使用了一个视觉变换器(Vision Transformer,简称 ViT)作为其视觉编码器。具体来说,文献中提到的是 ViT-B/16 架构,这表明它使用了基础大小(Base)的变换器,并且将图像分割成了 16×16 像素的小块。
- 文本编码器:BioCLIP 保留了 CLIP 的文本编码器,这是一个因果自回归变换器(Causal Autoregressive Transformer),它能够处理文本数据,并将文本转换成与视觉编码器输出相匹配的特征表示。
- 多模态对比学习:BioCLIP 采用了 CLIP 风格的多模态对比学习目标。这种学习目标旨在增强图像和文本之间的关联,最大化正样本对(图像和相应的文本描述)之间的相似度,同时最小化负样本对之间的相似度。
- 层次化分类:BioCLIP 利用了生物分类学的层次结构,学习与生命之树相一致的表示,将从界(Kingdom)到最远的分类群等级的分类标签”扁平化”成字符串,称为分类名称(taxonomic name)。这种层次化的标签空间通过自回归文本编码器自然嵌入到密集的标签空间中,使得模型能够学习到与生物分类学结构相一致的层次化表示。
- 训练策略:BioCLIP 采用了一种新颖的策略,结合了 CLIP 风格的多模态对比学习以及丰富的生物学分类学信息。模型通过学习匹配图像和相应的分类名称来训练,这有助于模型泛化到训练中未见过的分类群。
- 零样本和少样本学习:BioCLIP 支持零样本(zero-shot)和少样本(few-shot)分类,这意味着它可以在没有或只有很少的训练样本的情况下对新的分类群进行分类。
- 混合文本类型训练:BioCLIP 在训练时混合使用不同类型的文本(例如分类学名称、科学名称、通用名称),以提高模型在测试时的灵活性。
实验结果
BioCLIP 在多种细粒度生物学分类任务上展现出色性能,显著优于现有基线模型。在zero-shot 和 few-shot 学习中,BioCLIP的平均绝对改进达到了17%(zero-shot)和16%(few-shot)。内在评估显示,BioCLIP学习到了符合生命之树的层次表示,证明了其强大的泛化能力。
文章总结
- 作者介绍了 TREEOFLIFE-10M 和 BioCLIP,并展示了 BioCLIP 在生物学细粒度分类任务中的表现。
- 作者指出,尽管 CLIP 目标有效地学习了超过 450K 分类群的视觉表示,但 BioCLIP 本质上是被训练用于分类的。
- 未来的工作将进一步扩大数据规模,例如纳入超过 100M 研究级图像,并收集更丰富的物种外观文本描述,以便 BioCLIP 能够提取细粒度的性状级表示。
- 整体而言,这篇文献提出了一个创新的模型,旨在通过利用大规模的生物图像数据集来推动生物学领域的研究和保护工作,并通过计算机视觉技术来提高对生物多样性的认识和理解。
- 文章模型已经开源,可通过 Github 和 Hugging Face 使用。
真实案例测试
Github 中提供了一个 demo,我在 demo 中上传了一张自己的肥尾守宫(Hemitheconyx caudicinctus)照片,可惜因为太过小众没识别成功。Demo 识别出的概率最大的豹纹守宫(Eublepharis macularius,Leopard gecko)与肥尾守宫很相似,但也有一些比较显著的差别。
![图片[4]-CVPR 2014| BioCLIP:生命之树的视觉基础模型 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2024/05/Pasted-image-20240529093521.png)
相关链接
[1] 文章: https://arxiv.org/abs/2311.18803
[2] 审稿意见:https://openreview.net/forum?id=LvlqEaXJbe
[3] Github:https://imageomics.github.io/bioclip
[4] Hugging Face:https://huggingface.co/imageomics/bioclip
![图片[5]-CVPR 2014| BioCLIP:生命之树的视觉基础模型 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2021/09/wx-banner-website-20210914.png)













暂无评论内容